Week 11 [Fri, Mar 29th] - Topics
Guidance for the item(s) below:
Previously, you learned about design patterns, and some example design patterns. Let's continue that journey this week.
Guidance for the item(s) below:
First, let's learn two more widely-cited design patterns.
Can explain the Model View Controller (MVC) design pattern
Context
Most applications support storage/retrieval of information, displaying of information to the user (often via multiple UIs having different formats), and changing stored information based on external inputs.
Problem
The high coupling that can result from the interlinked nature of the features described above.
Solution
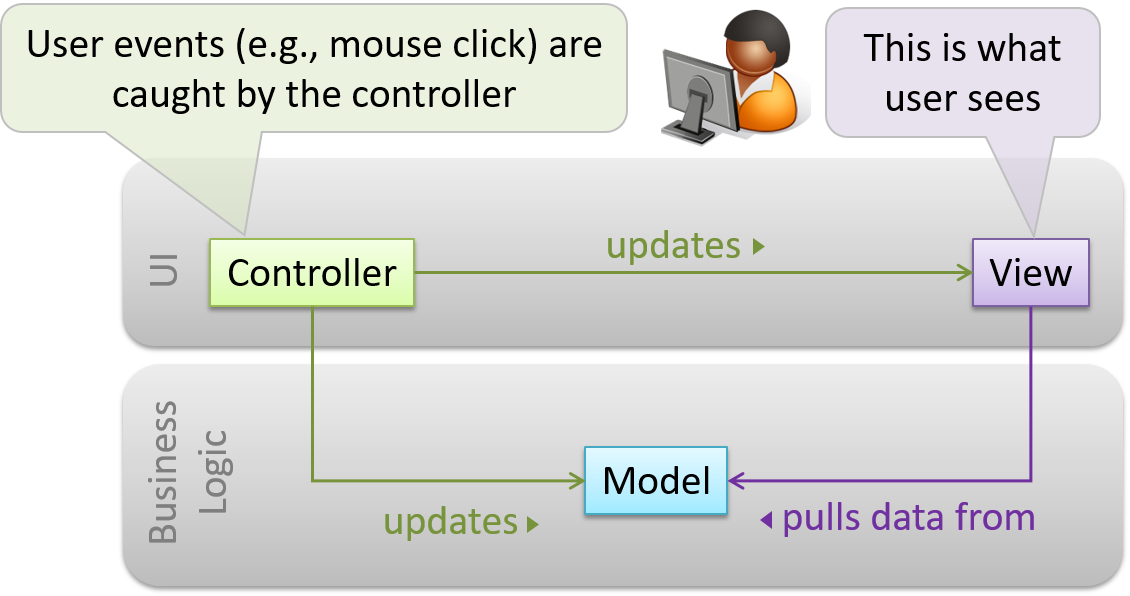
Decouple data, presentation, and control logic of an application by separating them into three different components: Model, View and Controller.
- View: Displays data, interacts with the user, and pulls data from the model if necessary.
- Controller: Detects UI events such as mouse clicks and button pushes, and takes follow up action. Updates/changes the model/view when necessary.
- Model: Stores and maintains data. Updates the view if necessary.
The relationship between the components can be observed in the diagram below. Typically, the UI is the combination of View and Controller.
Given below is a concrete example of MVC applied to a student management system. In this scenario, the user is retrieving the data of a student.
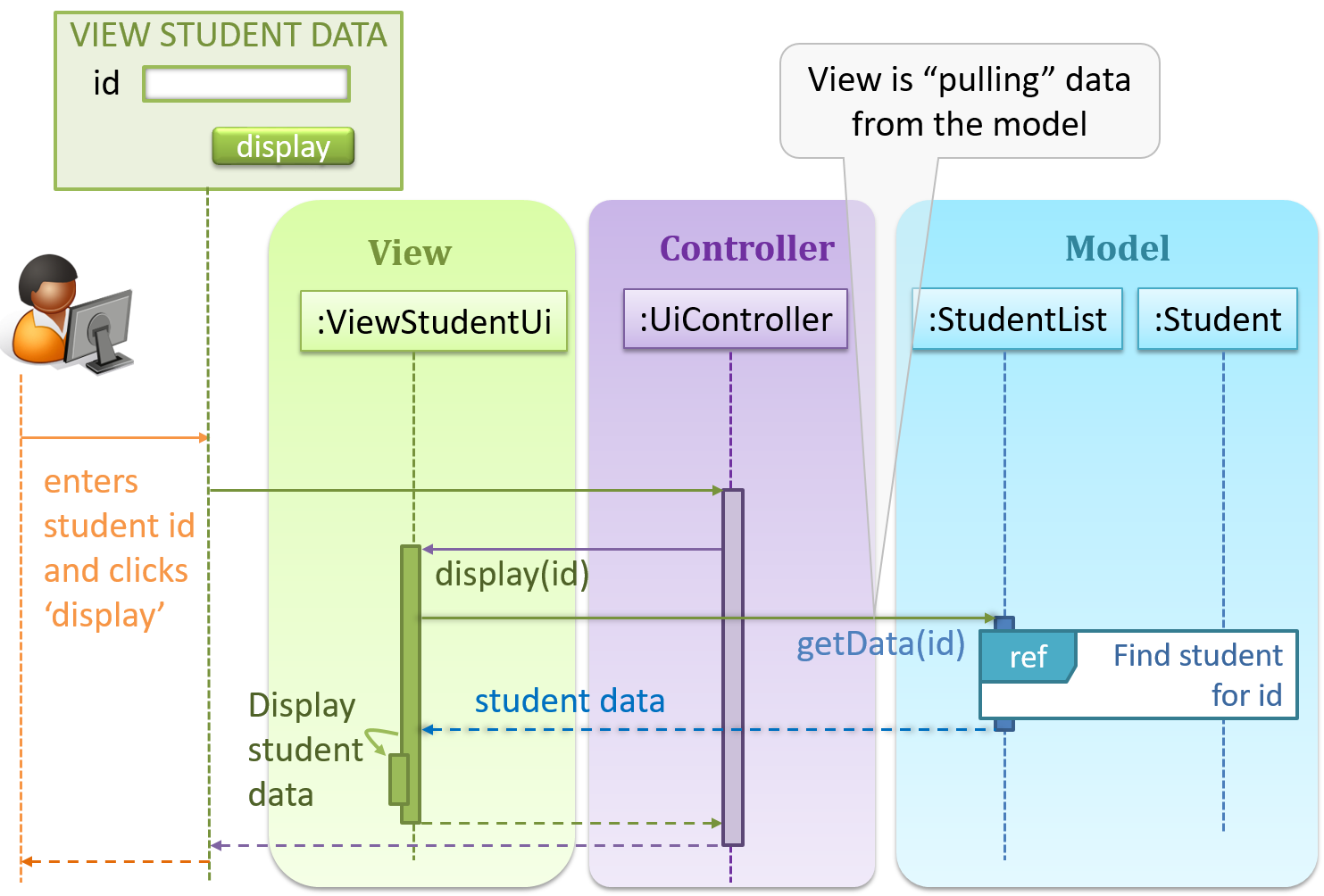
In the diagram above, when the user clicks on a button using the UI, the ‘click’ event is caught and handled by the UiController. The ref frame indicates that the interactions within that frame have been extracted out to another separate sequence diagram.
Note that in a simple UI where there’s only one view, Controller and View can be combined as one class.
There are many variations of the MVC model used in different domains. For example, the one used in a desktop GUI could be different from the one used in a web application.
Can explain the Observer design pattern
Context
An object (possibly more than one) is interested in being notified when a change happens to another object. That is, some objects want to ‘observe’ another object.
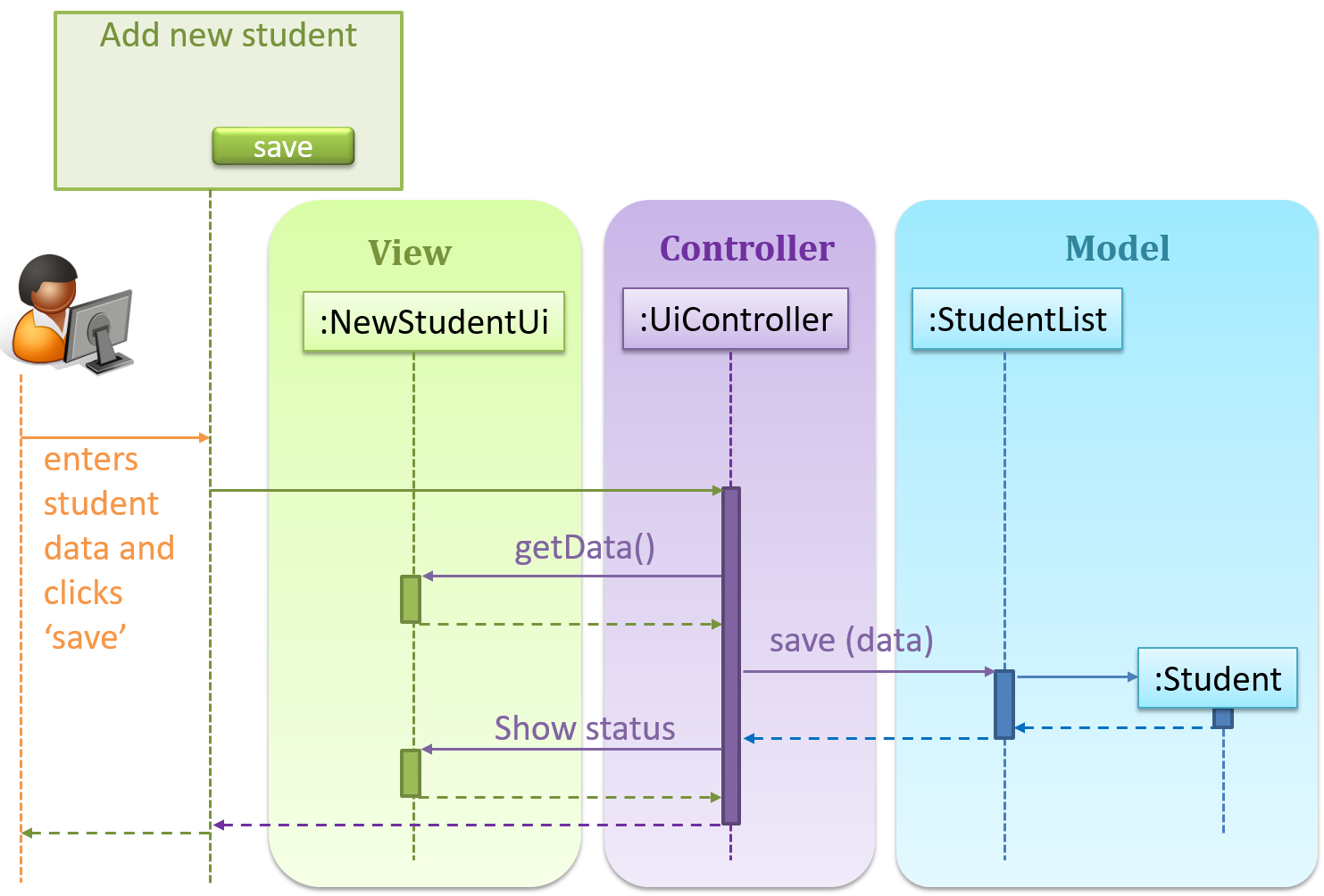
Consider this scenario from a student management system where the user is adding a new student to the system.
Now, assume the system has two additional views used in parallel by different users:
StudentListUi: that accesses a list of students andStudentStatsUi: that generates statistics of current students.
When a student is added to the database using NewStudentUi shown above, both StudentListUi and StudentStatsUi should get updated automatically, as shown below.
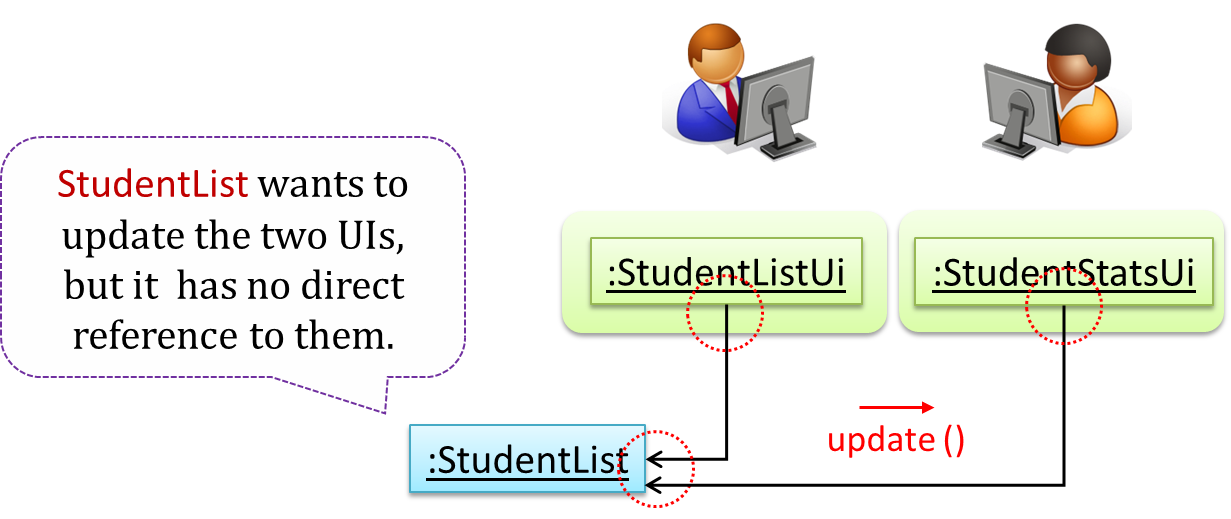
However, the StudentList object has no knowledge about StudentListUi and StudentStatsUi (note the direction of the navigability) and has no way to inform those objects. This is an example of the type of problem addressed by the Observer pattern.
Problem
The ‘observed’ object does not want to be coupled to objects that are ‘observing’ it.
Solution
Force the communication through an interface known to both parties.
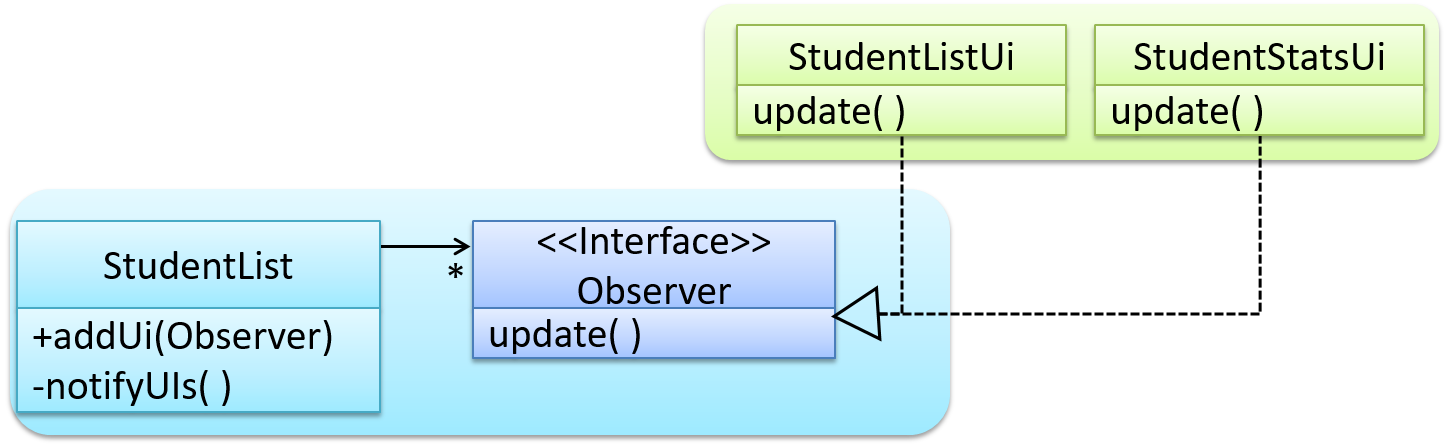
Here is the Observer pattern applied to the student management system.
During the initialization of the system,
First, create the relevant objects.
StudentList studentList = new StudentList(); StudentListUi listUi = new StudentListUi(); StudentStatsUi statsUi = new StudentStatsUi();Next, the two UIs indicate to the
StudentListthat they are interested in being updated wheneverStudentListchanges. This is also known as ‘subscribing for updates’.studentList.addUi(listUi); studentList.addUi(statsUi);Within the
addUioperation ofStudentList, all Observer object subscribers are added to an internal data structure calledobserverList.// StudentList class public void addUi(Observer o) { observerList.add(o); }
Now, whenever the data in StudentList changes (e.g. when a new student is added to the StudentList),
All interested observers are updated by calling the
notifyUIsoperation.// StudentList class public void notifyUIs() { // for each observer in the list for (Observer o: observerList) { o.update(); } }UIs can then pull data from the
StudentListwhenever theupdateoperation is called.// StudentListUI class public void update() { // refresh UI by pulling data from StudentList }Note that
StudentListis unaware of the exact nature of the two UIs but still manages to communicate with them via an intermediary.
Here is the generic description of the observer pattern:

<<Observer>>is an interface: any class that implements it can observe an<<Observable>>. Any number of<<Observer>>objects can observe (i.e. listen to changes of) the<<Observable>>object.- The
<<Observable>>maintains a list of<<Observer>>objects.addObserver(Observer)operation adds a new<<Observer>>to the list of<<Observer>>s. - Whenever there is a change in the
<<Observable>>, thenotifyObservers()operation is called that will call theupdate()operation of all<<Observer>>s in the list.
In a GUI application, how is the Controller notified when the “save” button is clicked? UI frameworks such as JavaFX have inbuilt support for the Observer pattern.
Guidance for the item(s) below:
Given below are a few more topics that continue the theme of design patterns, but have been made optional to reduce the course workload.
Guidance for the item(s) below:
The next topic is like 'design patterns at architecture level'. In fact, the MVC pattern you saw earlier comes close to this category too.
Can identify n-tier architectural style
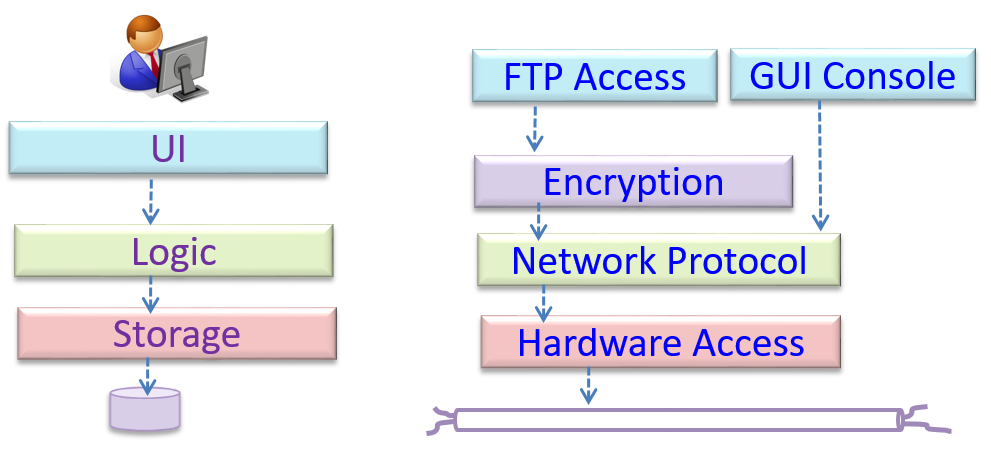
In the n-tier style, higher layers make use of services provided by lower layers. Lower layers are independent of higher layers. Other names: multi-layered, layered.
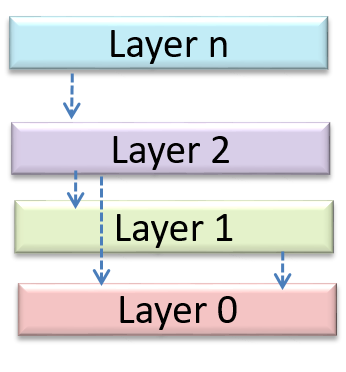
Operating systems and network communication software often use n-tier style.
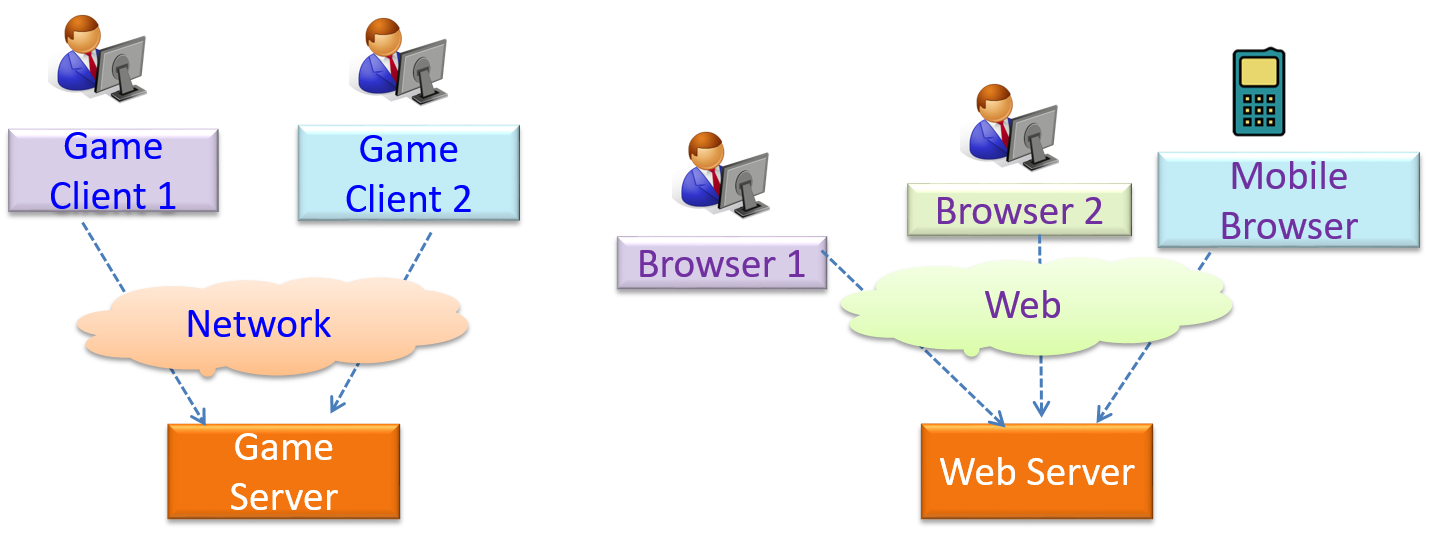
Can identify the client-server architectural style
The client-server style has at least one component playing the role of a server and at least one client component accessing the services of the server. This is an architectural style used often in distributed applications.
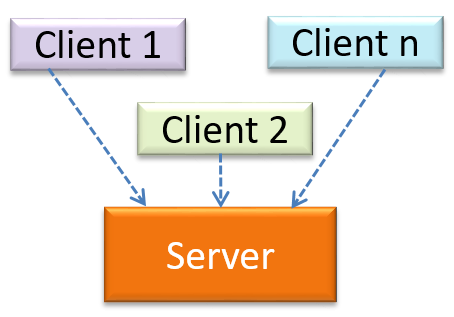
The online game and the web application below use the client-server style.
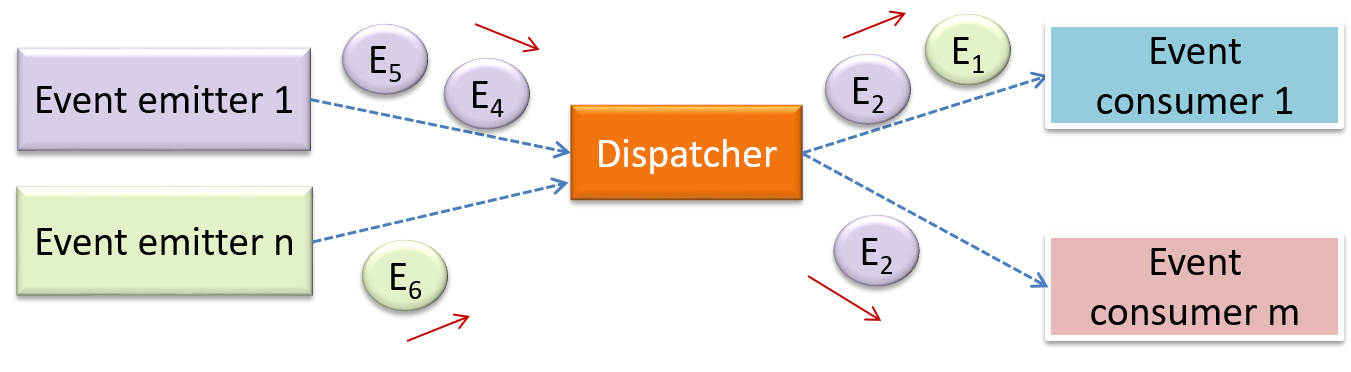
Can identify event-driven architectural style
Event-driven style controls the flow of the application by detecting from event emitters and communicating those events to interested event consumers. This architectural style is often used in GUIs.
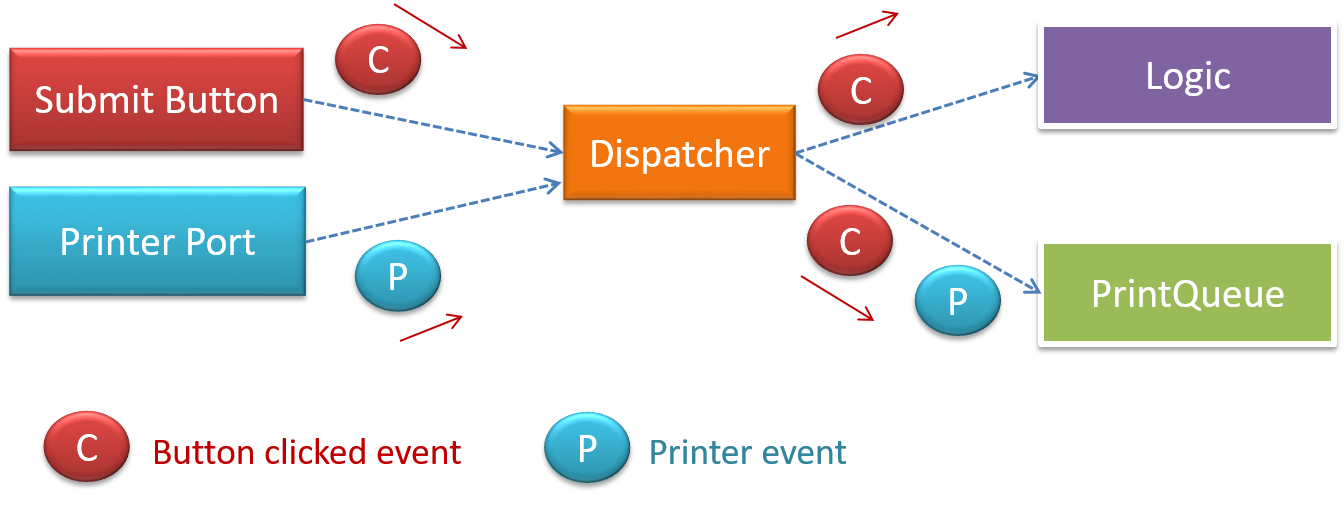
When the ‘button clicked’ event occurs in a GUI, that event can be transmitted to components that are interested in reacting to that event. Similarly, events detected at a printer port can be transmitted to components related to operating the printer. The same event can be sent to multiple consumers too.
Can identify transaction processing architectural style
The transaction processing style divides the workload of the system down to a number of transactions which are then given to a dispatcher that controls the execution of each transaction. Task queuing, ordering, undo etc. are handled by the dispatcher.
In this example from a banking system, transactions are generated by the terminals used by , which are then sent to a central dispatching unit, which in turn dispatches the transactions to various other units to execute.
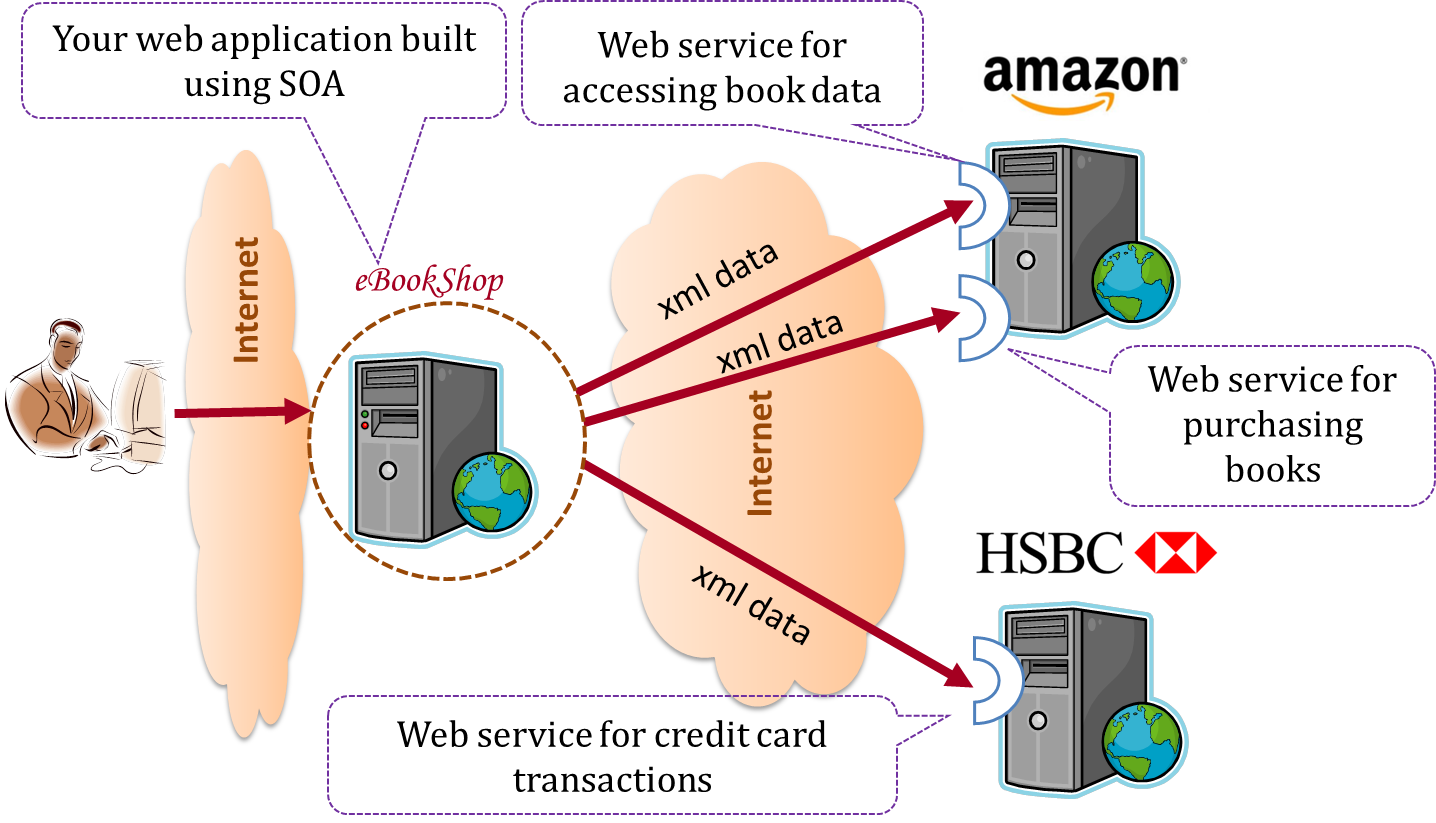
Can identify service-oriented architectural style
The service-oriented architecture (SOA) style builds applications by combining functionalities packaged as programmatically accessible services. SOA aims to achieve interoperability between distributed services, which may not even be implemented using the same programming language. A common way to implement SOA is through the use of XML web services where the web is used as the medium for the services to interact, and XML is used as the language of communication between service providers and service users.
Suppose that Amazon.com provides a web service for customers to browse and buy merchandise, while HSBC provides a web service for merchants to charge HSBC credit cards. Using these web services, an ‘eBookShop’ web application can be developed that allows HSBC customers to buy merchandise from Amazon and pay for them using HSBC credit cards. Because both Amazon and HSBC services follow the SOA architecture, their web services can be reused by the web application, even if all three systems use different programming platforms.
Follow up notes for the item(s) above:
As with design patterns, we covered only a few architecture styles. Although you didn't have to design an architecture in the tP, knowing the existence of these styles might come in handy in your future projects.
Guidance for the item(s) below:
Earlier, you learned that can improve the test case quality. Even when applying them, the number of test cases can increase when the SUT takes multiple inputs. Let's see how we can deal with such situations.
Guidance for the item(s) below:
Testing is the first thing that comes to mind when you hear 'Quality Assurance' but there are other QA techniques that can complement testing. Let's first take a step back and take a look at QA in general, followed by a look at some other QA techniques.
Guidance for the item(s) below:
Do you know the difference between a library and a framework?
Programmers often reuse code in various ways. The next few topics aim to clarify the difference between several forms reusable software comes in.
Guidance for the item(s) below:
While not examinable, the next few sections explain some basic cloud computing concepts that are relevant to software engineers.
Guidance for the item(s) below:
To complete the picture about UML, given below are a peek into the other types of UML diagrams.