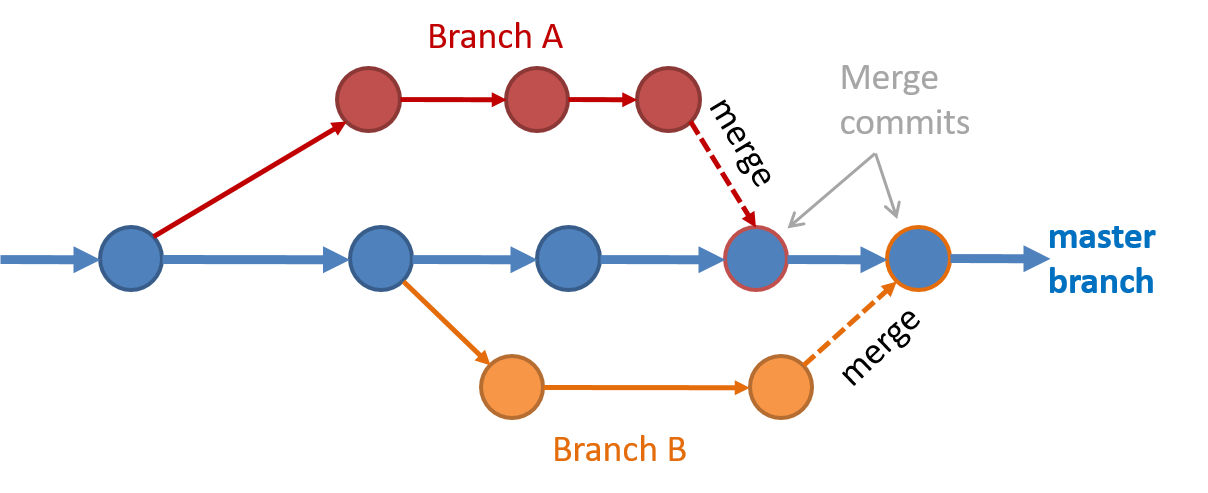
Branching is the process of evolving multiple versions of the software in parallel. For example, one team member can create a new branch and add an experimental feature to it while the rest of the team keeps working on another branch. Branches can be given names e.g. master, release, dev.
A branch can be merged into another branch. Merging usually results in a new commit that represents the changes done in the branch being merged.
 Branching and merging
Branching and merging Merge conflicts happen when you try to merge two branches that had changed the same part of the code and the RCS cannot decide which changes to keep. In those cases, you have to ‘resolve’ the conflicts manually.
RCS can be done in two ways: the centralized way and the distributed way.
Centralized RCS (CRCS for short) uses a central remote repo that is shared by the team. Team members download (‘pull’) and upload (‘push’) changes between their own local repositories and the central repository. Older RCS tools such as CVS and SVN support only this model. Note that these older RCS do not support the notion of a local repo either. Instead, they force users to do all the versioning with the remote repo.
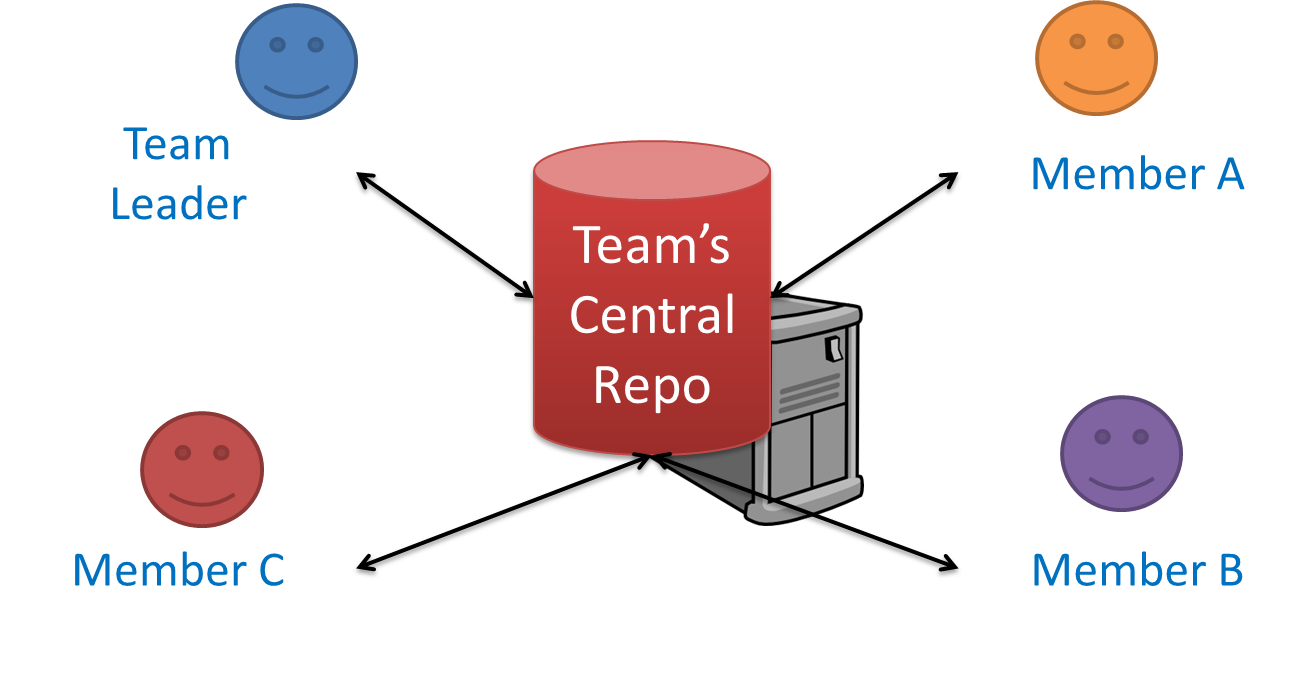
The centralized RCS approach without any local repos (e.g., CVS, SVN)
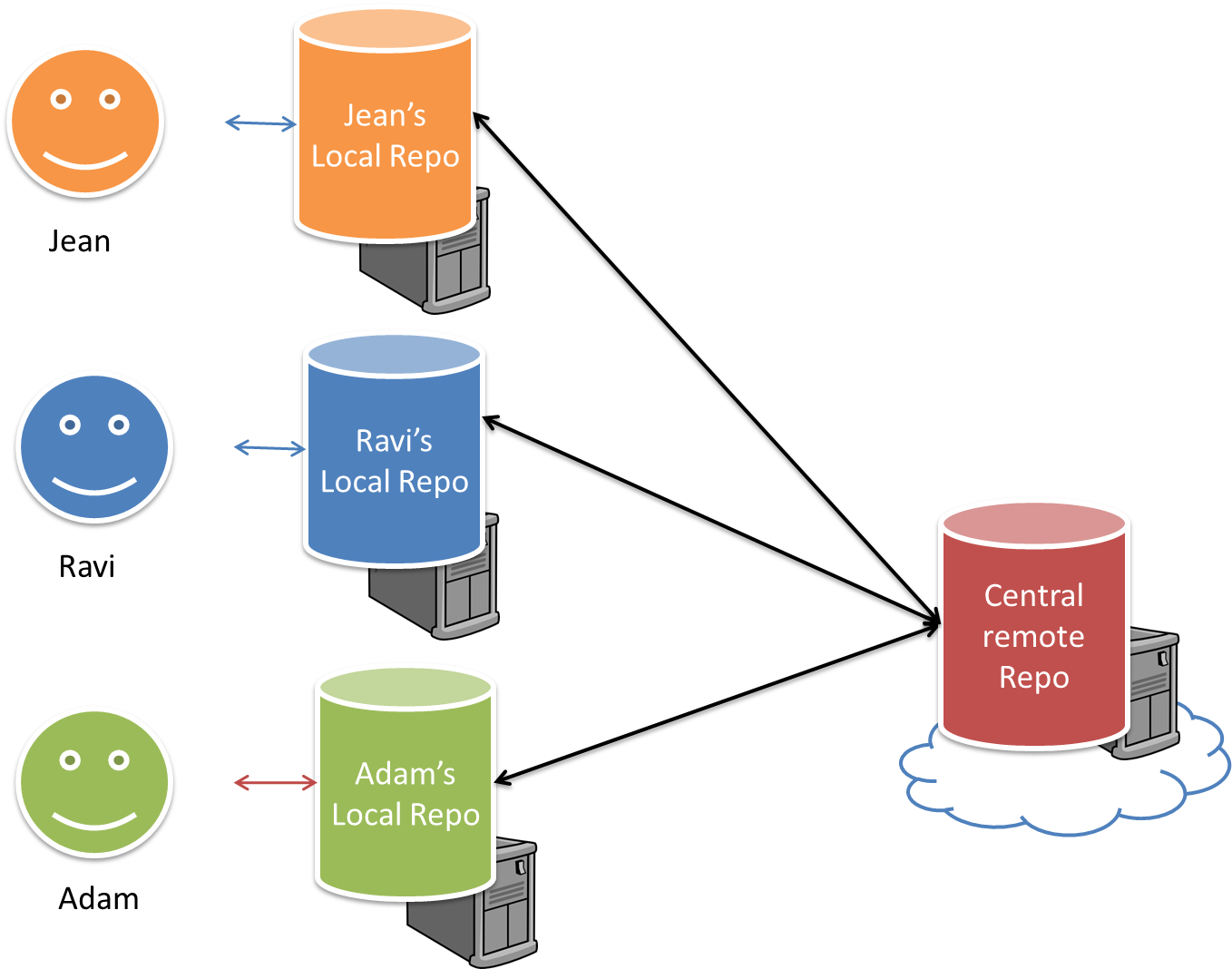
Distributed RCS (DRCS for short, also known as Decentralized RCS) allows multiple remote repos and pulling and pushing can be done among them in arbitrary ways. The workflow can vary differently from team to team. For example, every team member can have his/her own remote repository in addition to their own local repository, as shown in the diagram below. Git and Mercurial are some prominent RCS tools that support the distributed approach.
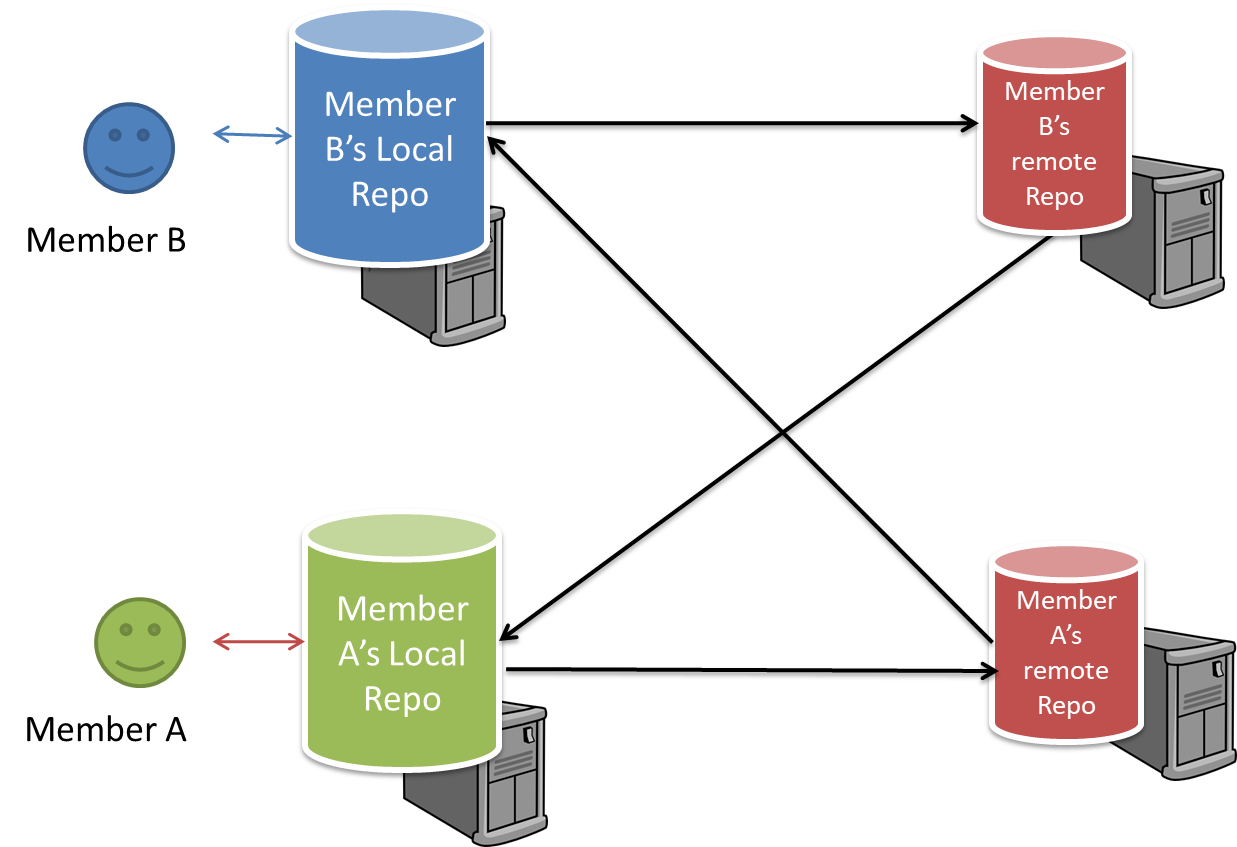
The decentralized RCS approach
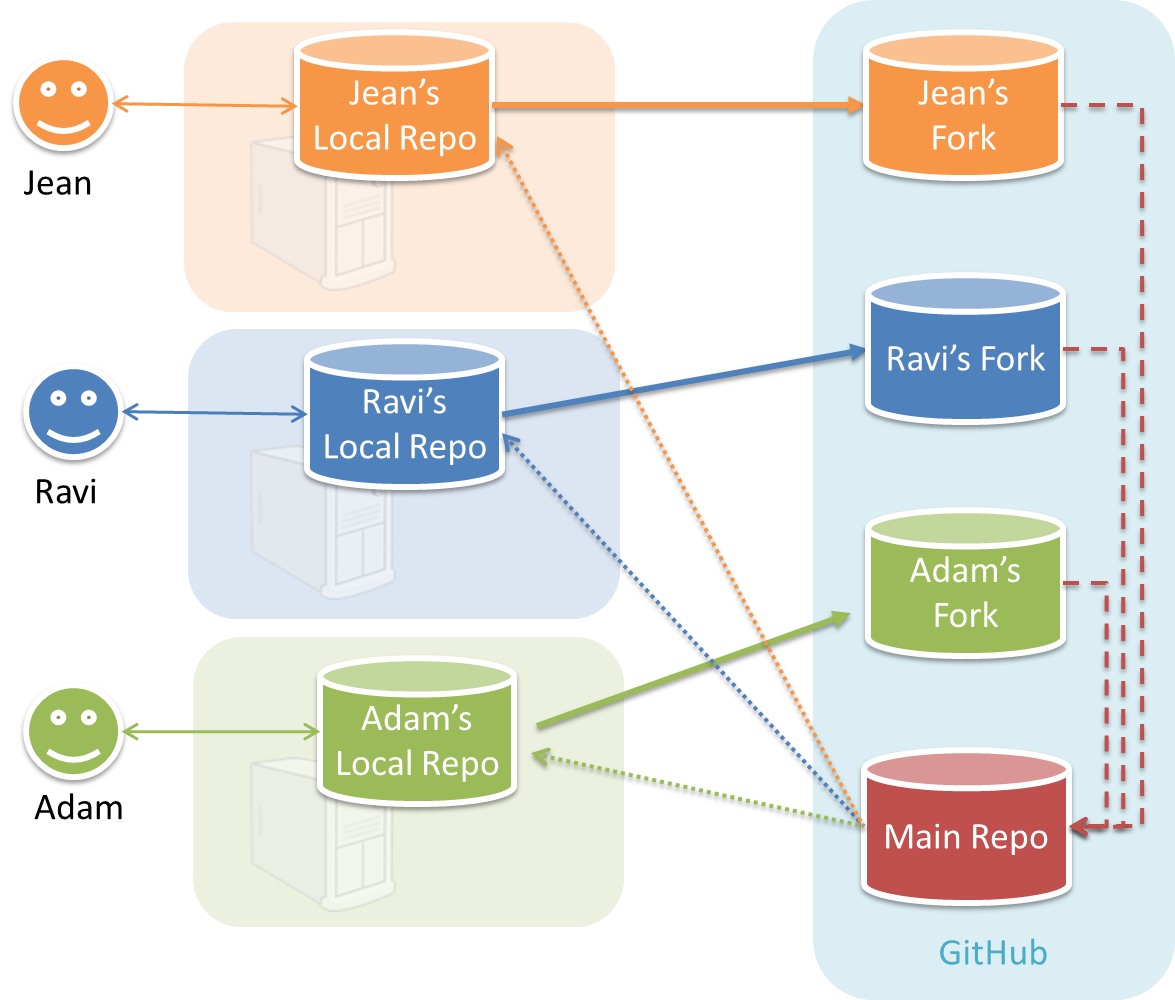
In the forking workflow, the 'official' version of the software is kept in a remote repo designated as the 'main repo'. All team members fork the main repo and create pull requests from their fork to the main repo.
To illustrate how the workflow goes, let’s assume Jean wants to fix a bug in the code. Here are the steps:
- Jean creates a separate branch in her local repo and fixes the bug in that branch.
Common mistake: Doing the proposed changes in themasterbranch -- if Jean does that, she will not be able to have more than one PR open at any time because any changes to themasterbranch will be reflected in all open PRs. - Jean pushes the branch to her fork.
- Jean creates a pull request from that branch in her fork to the main repo.
- Other members review Jean’s pull request.
- If reviewers suggested any changes, Jean updates the PR accordingly.
- When reviewers are satisfied with the PR, one of the members (usually the team lead or a designated 'maintainer' of the main repo) merges the PR, which brings Jean’s code to the main repo.
- Other members, realizing there is new code in the upstream repo, sync their forks with the new upstream repo (i.e. the main repo). This is done by pulling the new code to their own local repo and pushing the updated code to their own fork. If there are unmerged branches in the local repo, they can be updated too e.g., by merging the new
masterbranch to each of them.
Possible mistake: Creating another 'reverse' PR from the team repo to the team member's fork to sync the member's fork with the merged code. PRs are meant to go from downstream repos to upstream repos, not in the other direction.
One main benefit of this workflow is that it does not require most contributors to have write permissions to the main repository. Only those who are merging PRs need write permissions. The main drawback of this workflow is the extra overhead of sending everything through forks.
Feature branch workflow is similar to forking workflow except there are no forks. Everyone is pushing/pulling from the same remote repo. The phrase feature branch is used because each new feature (or bug fix, or any other modification) is done in a separate branch and merged to the master branch when ready. Pull requests can still be created within the central repository, from the feature branch to the main branch.
As this workflow require all team members to have write access to the repository,
- it is better to protect the main branch using some mechanism, to reduce the risk of accidental undesirable changes to it.
- it is not suitable for situations where the code contributors are not 'trusted' enough to be given write permission.